What is edge computing?
'Edge computing' is quickly becoming one of the most popular buzzwords in the BI space. It seems that every BI vendor is advertising how their tool is the best tool on the market for edge computing and building an IoT ecosystem. Only problem is, none of their customers knows what those things are.
Since edge computing is such a new concept, most BI customers don't really know what it is. If they don't know what it is, then there's no reason for them to invest in it. Edge computing and related concepts are still catching on in the BI space, so there's still a lot of unanswered questions.
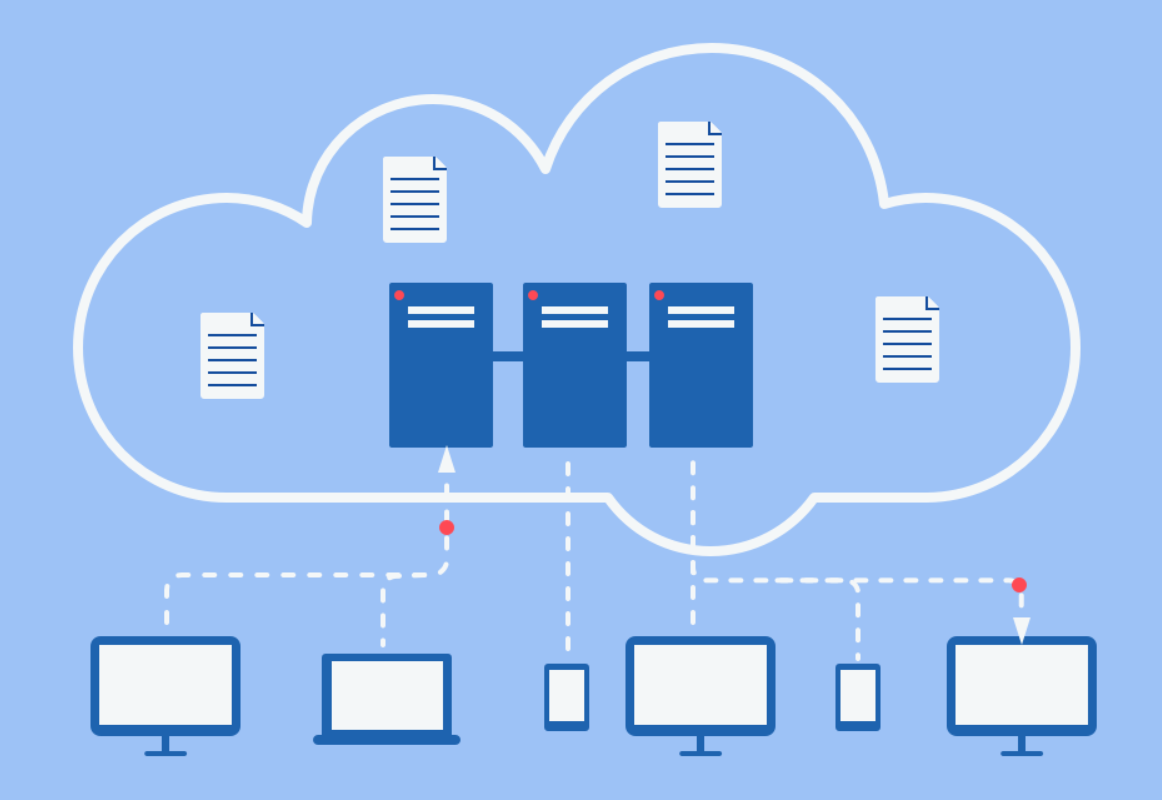
As the name suggests, edge computing describes the computing that goes on at the edge of a given network. The average computer network has a 'core' of servers and databases that act as a central hub, and then all sorts of devices that operate outside this core. Different devices operate at different distances from the core, and edge computing focuses exclusively on the devices that operate the furthest out.
In traditional computer networks, there aren't a huge amount of devices on the edges of the network. In general, the edge of a network is defined as where data is originally collected in its raw form. A business might have a handful of cash registers and maybe a security system making up the entirety of its network edge.
Nowadays, it's much more common to see businesses with dozens, hundreds, or even thousands of devices on the edge of their network. More and more devices are being built with Internet connectivity, building a network of connected devices known as the Internet of things. IoT devices have shifted edge computing from a niche discipline to one of the biggest trends in business computing.
With IoT devices, the amount of computing that businesses do on their network has gone way up. More and more devices are connected to the Internet and can transmit data, and companies have introduced these devices in their sales pipelines, manufacturing workflows, and marketing strategies.
A manufacturing company may connect its fabrication machines to the cloud, and receive real-time updates on the performance of their assembly line. A power company may outfit their substations with smart sensors to better respond to outages and manage consumption.
These are just some basic examples. Not every business will be able to take advantage of cloud computing and the Internet of Things in the same way; part of the challenge with edge computing is figuring out how to leverage its power in less technologically integrated industries.
Edge computing vs. cloud computing
Many tech experts are pushing edge computing as the logical next step past cloud computing. However, edge computing doesn't necessarily need to replace cloud computing; it's important to know how the two approaches are similar and where they differ.
Edge computing is both a subtype of cloud computing and an alternative to traditional cloud computing models. They both represent a huge step forward beyond on-premise computing which is tied to one physical location.
With cloud computing, much of the software and computing power that a business needs to operate is shifted off-premise, onto third-party servers and networks that are accessed remotely. This is a very effective cost-saving measure, and also allows businesses to access their data remotely from anywhere.
In the traditional cloud computing model, all of a company's data is transmitted to and stored in one central database or data warehouse, and then is parceled out to whatever application or team needs it. This mirrors the structure of on-premise solutions, which also feature centralized data warehouses. The difference is that cloud-based data warehouses can be accessed from anywhere.
However, there are still some downsides with the traditional cloud-based model that need solving. First, all data has to go through the central database, and this causes several issues with data access and data speed.
In extremely distributed networks, the delay between sending data to the central database and getting a response back is long enough to cause problems. While this isn't often an issue at smaller businesses with less complex operations, larger businesses come across this problem a lot
For example, a manufacturing device may be managed remotely with specialized software. When the device encounters an error, it may be a few seconds until it gets a response from its software about what to do about it. In that time, though, thousands of products may have been produced with errors.
This issue also affects consumer IoT devices. A brand of smart lights might route all of its customer's requests through a central database. This means it takes a few seconds for the command to go from the customer, to the database, to the smart lights. This process can never beat the speed of just flipping a light switch.
In cases like these, it's clear that companies want their internet-connected and IoT devices to have more autonomy. Edge computing allows for speedier operations at the fringes of a network, since devices on the edge don't necessarily need to communicate with a central database for orders.
Traditional cloud computing also struggles in terms of bandwidth. Many businesses have limits in the amounts of requests they can send to their central database in a given length of time. For businesses that go over these limits, it means surcharges and slowdowns.
Edge computing is a way to sidestep the central database in low-intensity situations, and clear up a lot of the data bottlenecks that exist closer to the center of the network. Less important traffic can skip the database, freeing up bandwidth for more important work.
Architecture of edge networks
So if businesses aren't sending data requests to their central server in edge computing, where are they sending the data to? In edge computing, some of the processing power of the central database is moved away from the center of the network in the form of data marts, local warehouses, and other decentralized data storage options.
In business intelligence, this often means that mission-critical data is stored in data marts unattached to the main business database. This way, users and devices don't have to query the central database for most of their mundane data requirements.
This helps businesses to act quicker and move in a more agile way. For example, a smart thermostat might send data to a database every time it cycles on or off. Multiplied by millions of homes, this could mean billions of data requests a day to a central server. Even the largest businesses don't have the bandwidth necessary to effectively handle that many requests.
With edge computing, the thermostat company can route routine data transfers away from the central server, and store that data in places that are more decentralized. Not only does this improve data speeds and bandwidth requirements, it allows smart devices to react quicker to changes or user input.
Edge computing's data architecture also makes it more resilient to data outages. In traditional cloud computing, businesses use third-party services to store and manage their data. While there are many vendors in the industry, most of the market has coalesced around three big players - Amazon Web Services, Google Cloud, or Microsoft Azure.
This centralization has its advantages; it allows businesses to access economies of scale in their data management and makes interoperability between systems easier. However, it does come with some downsides. Since these three vendors control the majority of business's data, if there's an outage that prevents access to their databases, then large portions of a business's operations can become inoperable.
When AWS experienced an outage in December 2021, it affected huge swaths of the tech industry, from social media to music streaming to app-connected ceiling fans. These sorts of outages are becoming more common, and have started to last longer than similar outages in the past.
When these outages occur, it's financially devastating. Amazon estimates that their retail businesses lose up to $70,000 per minute while the servers they use to manage orders are down. It's even worse for other businesses, who can't do anything during the outage and have to wait for their third-party vendor to get their act together.
With edge computing, businesses can mitigate many of the most harmful impacts of this unplanned downtime. At a manufacturing business, Internet-connected assembly devices might rely on orders from a central database. When these orders get interrupted due to outage, the devices can't function and the assembly line stalls.
In a more decentralized data approach, these devices wouldn't have to rely on the central database as much, and could still operate effectively. This approach is also useful for businesses that operate in remote areas that don't always have Internet access.
Edge computing, demystified
As businesses connect more devices to the cloud, and collect more data from their clients and customers, edge computing will become more and more mainstream. Right now, its utility is somewhat limited to enterprise-scale businesses that have valuable IoT devices, but soon, every business will be able to take advantage of computing at the periphery.
If your business is having trouble managing its data, edge computing may not be the answer just yet. However, business intelligence tools can help with more mundane data requirements. The advantages that edge computing will bring to businesses a decade from now, business intelligence can help to bring today.
For more information on how business intelligence software can meet your business's needs, contact us today. Our team of experts can provide you with a no-cost, no-obligation consultation to connect your business to the tool that'll work the best.